文章來源:大數據文摘|BigDataDigest

長期以來,我們一直在與機器溝通:編寫程式碼 — 建立程式 — 執行任務。
然而,這些程式並非是用人類“自然語言“編寫的,像Java、Python、C和C ++語言,始終考慮的是”機器能夠輕鬆理解和處理嗎?”
“自然語言處理”(Natural Language Processing,NLP)的目的與此相反,它不是以人類順應機器的方式學習與它們溝通,而是使機器具備智力,學習人類的交流方式。其意義更為重大,因為技術的目的本來就是讓我們生活得更輕鬆。

自然語言處理,實際上是人工智慧和語言學的交叉領域,但多年來,僅在語音轉錄、語音命令執行、語音關鍵詞提取的工作上兢兢業業,規規矩矩,應用到人機互動,就顯得十分吃力。

因為在語料預處理階段,NLP通常直接給出“斷句”,比如 “訂一張明天從北京到杭州的機票,國航頭等艙”,經過NLP模型處理後,機器給出的輸出如下:

儘管準確率高,但在這背後,我們並不知道機器理解了什麼。由於足夠好用,人們也就不多問了。
而在更加複雜的任務中,比如機器翻譯,基於深度學習的編碼、解碼架構會將原句子轉換成我們根本不熟悉的樣子,也就是在無窮維空間中的點。
一旦機器翻譯出錯,我們開啟這個空間的時候,才發現這些點和周圍其他點(其他句子)構成的形態,猶如荒蕪宇宙裡零落的星星那樣縹緲和神秘。

研究人員試圖向神經網路新增引數以提高它們在語言任務上的表現,然而,語言理解的根本問題是“理解詞語和句子下隱藏的含義“。
近日,倫斯勒理工學院的兩位科學家撰寫了一本名為《人工智慧時代語言學》的書,探討了目前的人工智慧學習方法在自然語言理解(Natural Language Understanding,NLU)中的瓶頸,並嘗試探索更先進的智慧體的途徑。
AI必須從“處理”自然語言到“理解”自然語言。
機器“記錄”了資料並不意味著“理解”了資料。近幾十年來,機器學習演算法一直嘗試完成從NLP 到 NLU 的轉型。過去,機器學習曾長期承載著轉型使命的榮光。

機器學習模型是一種知識精益系統,它試圖透過統計詞語對映來回答上下文關係。在這些模型中,上下文是由詞語序列之間的統計關係形成的,而非詞語背後的含義。自然,資料集越大、示例越多樣化,機器對上下文關係的理解越精確。
但作者認為,機器學習終將失寵,因為它們需要太多的算力和資料來自動設計特徵、建立詞彙結構和本體,以及開發將所有這些部分結合在一起的軟體系統。而且,機器人也不知道自己在做什麼,以及為什麼這樣做。它們解決問題的方法不像人類 — 不依賴與世界、語言或自身的互動。因此,它們無法理解兩個人長時間對話時,對同一件事情的描述越來越簡短的情景,也就是文字缺失現象。
巨大人工成本使機器學習陷入瓶頸,並迫使人們尋求其他方法來處理自然語言, 並導致了自然語言處理中經驗主義正規化(認為語言理解起源於感覺)的出現。
具有“感覺”的人工智慧,或許會在自然語言處理上有三個突破:
透過語言交流啟用感覺模型,並以此承載記憶,從而可以應對人類之間交流時的文字缺失現象,實現“默契”(正確)的解碼;
理解語言的上下文相關含義,並從單詞和句子的歧義中找到合適的理解,以及從感覺世界中尋找更強的約束和限制;
向它們的人類合作者解釋它們的想法、行動和決策;
與人類一樣,機器也需要在世界互動時保持終身學習。而機器學習由於將可壓縮性和可學習性對等起來,並且限於表面的符號統計關係理解,以及不可解釋性等原因,不可避免丟失背景資訊,而做不到上述層次的理解。
總之,機器要理解自然語言,感覺經驗是必不可少的。這與 Jürgen Schmidhuber在虛擬的遊戲環境中設計的智慧體是類似的邏輯,研究人員不會讓智慧體學習侷限於單一的決策輸出,而是逐步透過與虛擬世界互動,首先建立對虛擬世界的表徵模型,再基於表徵模型去進行決策。
正如 McShane 和 Nirenburg 在他們的書中指出的那樣,“ 語言理解不能與整體的認知過程區分開來,啟發機器人理解語言也要運用其他感知(例如視覺、觸覺)。”正如在現實世界中,人類也是利用他們豐富的體態動作來填補語言表達的空白。
經驗和數據驅動的革命
20世紀90年代初,一場統計革命席捲了人工智慧 (AI),並在 2000 年代達到高潮。神經網路化身為現代深度學習 (DL) 凱旋歸來,並席捲了人工智慧的所有子領域。儘管深度學習最具爭議的應用是自然語言處理 (NLP),但仍舊帶來了經驗主義的轉向。
NLP 中廣泛使用資料驅動的經驗方法有以下原因:符號和邏輯方法未能產生可擴充套件的 NLP 系統,導致 NLP (EMNLP,此指資料驅動、基於語料庫的短語,統計和機器學習方法)中所謂的經驗方法的興起。

這種向經驗主義轉變的動機很簡單:在我們深入瞭解語言如何運作以及如何與我們口語談論的內容相關之前,經驗和資料驅動的方法可能有助於構建一些實用的文字處理應用程式。
正如EMNLP的先驅之一肯尼思·丘奇(Kenneth Church)所解釋的,NLP資料驅動和統計方法的擁護者對解決簡單的語言任務感興趣,其動機從來不是暗示語言就是這樣運作的,而是”做簡單的事情總比什麼都不做好”。
丘奇認為,這種轉變的動機被嚴重誤解,他們以為這個“可能大致正確的”( Probably Approximately Correct ,PAC)正規化將擴充套件到完全自然的語言理解。

“新一代和當代的NLP研究人員在語言學和NLP的理解上有差別,因此,這種被誤導的趨勢導致了一種不幸的狀況:堅持使用”大語言模型”(LLM)構建NLP系統,這需要巨大的計算能力,並試圖透過記住海量資料來接近自然語言。
這幾乎是徒勞的嘗試。我們認為,這種偽科學方法不僅浪費時間和資源,而且引誘新一代年輕科學家認為語言只是資料。更糟糕的是,這種方法會阻礙自然語言理解(NLU)的任何真正進展。
相反,現在是重新思考 NLU 方法的時候了。因為我們確信,對 NLU 的”大資料”方法不僅在心理上、認知上甚至計算上都是難以操作的,而且這種盲目的資料驅動 NLU 方法在理論和技術上也有缺陷。
語言處理與語言理解
雖然 NLP(自然語言處理)和 NLU(自然語言理解)經常互換使用,但兩者之間存在巨大差異。事實上,認識到它們之間的技術差異將使我們認識到資料驅動的機器學習方法。雖然機器學習可能適合某些 NLP 任務,但它們幾乎與 NLU 無關。
考慮最常見的”下游 NLP”任務:
綜述 — 主題提取 — 命名實體識別(NER) — (語義)搜尋 — 自動標記 — 聚類
上述所有任務都符合所有機器學習方法的基礎可能大致正確(PAC) 正規化。具體來說,評估一些NLP系統在上述任務的效能是相對主觀的,沒有客觀標準來判斷某些系統提取的主題是否優於另一個主題。
然而,語言理解不承認任何程度的誤差,它們要充分理解一個話語或一個問題。

舉個例子,針對這句話,自然語言理解就需要考慮多種可能:我們有一個退休的BBC記者,曾在冷戰期間駐紮在一個東歐國家嗎?
某些資料庫對上述查詢將只有一個正確的答案。因此,將上述內容轉換為正式的結構化查詢語言查詢是巨大的挑戰,因為我們不能搞錯任何錯誤。
這個問題背後的”確切”思想涉及:
正確解釋”退休的BBC記者” — — 即作為所有在BBC工作的記者,現在退休了。
透過保留那些在某個”東歐國家”工作的”退休BBC記者”,進一步過濾上述內容。
除了地理限制之外,還有一個時間限制,即這些”退休的BBC記者”的工作時間必須是”冷戰期間”。
以上意味著將介詞短語為”在冷戰期間”,而不是”一個東歐國家”(如果”冷戰期間”被替換為”具有華沙成員資格”,就要考慮不同的介詞短語’)
做正確的量化範圍:我們正在尋找的不是在 “一些” 東歐國家工作的記者, 而是“任何”在“任何”東歐國家工作的記者。
上述具有挑戰性的語義理解功能都不能”大致”或”可能”正確 — — 而是應該絕對正確。換言之,我們必須從對上述問題的多種可能解釋中得到一個唯一的含義。
總而言之,對普通口語的真正理解與單純的文字(或語言)處理是完全不同的問題。在文字(或語言)處理中,我們可以接受近似正確的結果。
這時候,我們應該可以清楚地明白:為什麼NLP與NLU不同,為什麼NLU對機器來說是困難的。但是NLU 的困難根源究竟是 什麼?
為什麼 NLU 很困難:文字容易丟失
首先是”缺失文字現象”(MTP),我們認為它是自然語言理解中所有挑戰的核心。語言交流如下圖所示:
演講者將思想“編碼”為某種自然語言中的話語,然後聽眾將話語“解碼”為演講者打算/希望傳達的思想。”解碼”過程是NLU中的”U” — 即理解話語背後的思想。
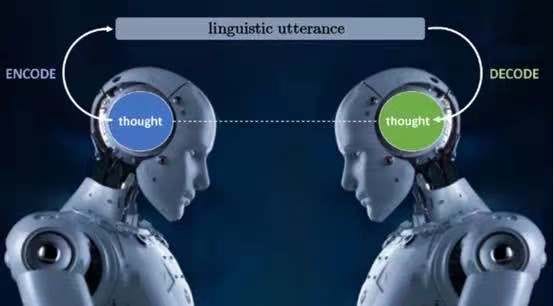
此外,”解碼”過程中需要沒有任何誤差,才能從說話者的話語中,找出唯一一種意在傳達的含義。這正是NLU困難的原因。
在這種複雜的通訊中,有兩種最佳化通訊的方案:
1.說話者可以壓縮(和最小化)在思想編碼中傳送的資訊量,並且聽者做一些額外的工作解碼(解壓縮)話語;
2.演講者多做一部分工作,把所有想要傳達的思想資訊告訴聽者,減少聽者的工作量;
這兩種過程都在發生和演進,最後似乎也得到了不錯的平衡嗎,說話者和聽者的總體工作都得到了同樣的最佳化。
該最佳化減少了說話者的編碼資訊,忽略了假設聽眾已知的其他資訊,但不會造成對話的背景資訊丟失。
舉個例子,對比下面黃色框中的未最佳化的文字和綠色框中最佳化的(等效但小得多的)文字。

綠色框中較短的資訊(我們通常就是這樣說話的)傳達了與較長的盒子相同的思想。通常,我們不會明確說明所有其他內容,因為我們都知道。這種技能幾乎花了人類20萬年的進化。
但這就是NLU的問題所在:機器不知道我們遺漏了什麼,它們不知道我們都知道什麼。
最終結果是NLU非常困難,如果它們不能以某種方式”整理”我們話語的所有的含義,那麼軟體程式將永遠不能完全理解我們話語背後的想法。
NLU的挑戰,並不是解析,阻止,POS標記,命名實體識別等, 而是解釋或揭示那些缺失的資訊。並隱含地假定為共享和共同的背景知識。
在此背景下,我們現在提供三個原因,說明為什麼機器學習和資料驅動的方法不會為自然語言理解提供解決方案。
1、ML 方法甚至與 NLU 無關:ML 是壓縮的,語言理解需要解壓縮
上述討論(希望)是一個令人信服的論點,即機器的自然語言理解由於MTP(媒體傳輸協議,Media Transfer Protocol)而變得困難,因為我們日常口語被高度壓縮,因此”理解”的挑戰在於未壓縮(或發現)缺失的文字。
機器的語言理解是困難的,因為機器不知道我們都知道什麼。但 MTP 現象正是為什麼資料驅動和機器學習方法雖然在某些 NLP 任務中可能很有用,但與 NLU 甚至不相關的原因。在這裡,我們提出這個證據:
機器可學習性(ML) 和可壓縮性(COMP)之間的等價性已在數學上建立。即已經確定,只有在資料高度可壓縮(未壓縮的資料有大量冗餘)時,才能從資料集中學習,反之亦然。
雖然可壓縮性和可學習性之間的證明在技術上相當複雜,但其實很容易理解:學習是關於消化大量資料並在多維空間中找到一個”覆蓋”整個資料集(以及看不見的的函式具有相同模式/分佈的資料)。
因此,當所有資料點都可以壓縮時,就會發生可學習性。但是 MTP 告訴我們 NLU 是關於解壓縮的。因此,我們梳理出以下內容:
機器學習是關於發現將大量資料概括為單一函式。另一方面,由於MTP,自然語言理解需要智慧的”不壓縮”技術,可以發現所有缺失和隱含的假定文字。因此,機器學習和語言理解是不相容的 — — 事實上,它們是矛盾的。
2、ML 方法甚至與 NLU 無關:統計上的無意義
ML 本質上是一種基於在資料中找到一些模式(相關性)的正規化。因此,該正規化的希望是在捕捉自然語言中的各種現象時,發現它們存在統計上的顯著差異。但是,請考慮以下事項):
獎盃不適合在手提箱,因為它是太 :1a.小 ;1b.大
請注意,”小”和”大”(或”開啟”和”關閉”等)等反義詞/反義詞以相同的機率出現在相同的上下文中。這樣,(小)和(大)在統計上等效的,但即使是一個4歲(小)和(大)是顯著不同:”它”在(小)是指”手提箱”而在(大)中它指的是”獎盃”。基本上,在簡單的語言中,(1 a ) 和 (1 b ) 在統計上是等價的,儘管在語義上遠非如此。因此,統計分析不能建模(甚至不能近似)語義 — — 就這麼簡單!
人們可以爭辯說,有了足夠的例子,一個系統可以確立統計學意義。但是,需要多少個示例來”學習”如何解決結構中的引用(如 (1)中的引用)?
在機器學習/資料驅動的方法中,沒有型別層次結構,我們可以對”包”、”手提箱”、”公文包”等進行概括性陳述,所有這些宣告都被視為通用型別”容器”的子型別。因此,以上每個模式,在純資料驅動的正規化中,都是不同的,必須在資料中分別”看到”。
如果我們在語義差異中加入上述模式的所有小語法差異(例如將”因為”更改為”雖然”,這也更改了”它”的正確引用),那麼粗略計算告訴我們,機器學習/資料驅動系統需要看到上述 40000000 個變體,以學習如何解決句子中的引用。如果有的話,這在計算上是不可信的。正如Fodor和Pylyshyn曾經引用著名的認知科學家喬治.米勒( George Miller),為了捕捉 NLU 系統所需的所有句法和語義變化,神經網路可能需要的特徵數量超過宇宙中的原子數量!這裡的寓意是:統計無法捕捉(甚至不能近似)語義。
3、ML 方法甚至與 NLU 無關:意圖
邏輯學家們長期以來一直在研究一種語義概念,試圖用語義三角形解釋什麼是”內涵”。
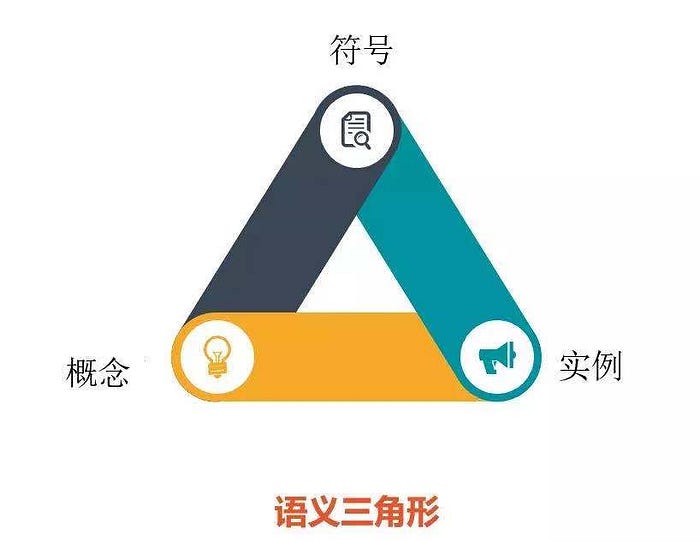
一個符號用來指代一個概念,概念可能有實際的物件作為例項,但有些概念沒有例項,例如,神話中的獨角獸只是一個概念,沒有實際的例項獨角獸。類似地,”被取消的旅行”是對實際未發生的事件的引用,或從未存在的事件等。
因此,每個”事物”(或認知的每一個物件)都有三個部分:一個符號,符號所指的概念以及概念具有的具體例項。我有時說,因為概念”獨角獸”沒有”實際”例項。概念本身是其所有潛在例項的理想化模板(因此它接近理想化形式柏拉圖)
一個概念(通常由某個符號/標籤所指)是由一組屬性和屬性定義,也許還有額外的公理和既定事實等。然而,概念與實際(不完美)例項不同,在數學世界中也是如此。因此,例如,雖然下面的算術表示式都有相同的擴充套件,但它們有不同的語氣:
內涵決定外延,但外延本身並不能完全代表概念。上述物件僅在一個屬性上相等,即它們的值在許多其他屬性上是不同的。在語言中,平等和同一性不能混淆,如果物件在某些屬性值中是平等的,則不能認為物件是相同的。

因此,雖然所有的表示式評估相同,因此在某種意義上是相等的,但這只是它們的屬性之一。事實上,上述表示式有幾個其他屬性,例如它們的語法結構、操作員數量、操作次數等。價值(這只是一個屬性)稱為外延,而所有屬性的集合是內涵。雖然在應用科學(工程,經濟學等),我們可以安全地認為它們相等僅屬性,在認知中(尤其是在語言理解中),這種平等是失敗的!下面是一個簡單的示例:
假設(1)是真的,即假設(1)真的發生了,我們看到了/ 見證了它。不過,這並不意味著我們可以假設(2)是真的,儘管我們所做的只是將 (1) 中的 ‘1b’ 替換為一個(假設)等於它的值。所以發生了什麼事?
我們在真實陳述中用一個被認為與之相等的物件替換了一個物件,我們從真實的東西中推斷出並非如此的東西!雖然在物理科學中,我們可以很容易地用一個屬性來替換一個等於它的物體,但這在認知上是行不通的!下面是另一個可能與語言更相關的示例:
透過簡單地將”亞歷山大大帝的導師”替換為與其相等的值,即亞里士多德,我們得到了(2),這顯然是荒謬的。同樣,雖然”亞歷山大大帝的導師”和”亞里士多德”在某種意義上是平等的(它們都具有相同的價值作為指稱),這兩個思想物件在許多其他屬性上是不同的。那麼,這個關於”內涵”的討論有什麼意義呢?
自然語言充斥著內涵現象,因為語言具有不可忽視的內涵。但是機器學習/資料驅動方法的所有變體都純粹是延伸的 — — 它們以物體的數字(向量/緊張)表示來運作,而不是它們的象徵性和結構特性,因此在這個正規化中,我們不能用自然語言來模擬各種內涵。
順便說一句,神經網路純粹是延伸的,因此不能表示內涵,這是它們總是容易受到對抗性攻擊的真正原因,儘管這個問題超出了本文的範圍。
結束語
我在本文中討論了三個原因,證明機器學習和資料驅動方法甚至與 NLU 無關(儘管這些方法可用於某些本質上是壓縮任務的文字處理任務)。以上三個理由本身都足以結束這場誇張的自然語言理解的數字工程。
人類在傳達自己的想法時,其實是在傳遞高度壓縮的語言表達,需要用大腦來解釋和”揭示”所有缺失但隱含假設的背景資訊。
語言是承載思想的人工製品,因此,在構建越來越大的語言模型時,機器學習和資料驅動方法試圖在嘗試找到資料中甚至不存在的東西時,徒勞地追逐無窮大。
我們必須認識到,普通的口語不僅僅是語言資料。
公眾號:大数据文摘









